A few weeks ago, I posted a “first look” blog about my early experiences testing Microsoft 365 Copilot. I approached Copilot from the perspective of an average and untrained user who just wanted to get his questions answered. I purposefully didn’t read any of the documentation or try any specific prompt engineering… just as an average user would, I jumped in and started doing stuff, then I wrote up the results.
That first-look generated a lot of attention after it was posted on Hacker News, which was briefly fun, and led to a running series of conversations and tests with my old friend Scott Schnoll from Microsoft. Based on my discussions with Scott, and what I learned from them, I wanted to recap the tests and see if any of the results had changed.
Before I do that, let’s talk a little about the Copilot “system” itself. I put “system” in quotes to emphasize that Copilot is really a system of systems built on top of, and into, various existing parts of the Microsoft 365 substrate. What most people think of as the AI piece of Copilot (the LLM) is only one part of the overall system. Microsoft has integrated the LLM with tenant data, web search, and (some of) the Microsoft 365 Apps suite. The Copilot experience you see is delivered by this combination, not just by the LLM alone. The LLM is based on the GPT family of engines from OpenAI; GPT can perform a wide range of content-creation tasks (which is why it’s called a “generative” AI tool), including generating original content that looks like it was written or drawn by a human. Copilot uses private instances of this LLM in Microsoft datacenters that mimic natural language based on patterns from large amounts of training data.
Completely apart from the work done to train the underlying global and tenant models, Microsoft has added its own proprietary code. Copilot iteratively processes output from multiple components and orchestrates them: your user prompt is combined with grounding data, history from your chat or prompt sessions, and a default system prompt customized for Microsoft 365. This default prompt helps outline rules for interacting responsibly with the user, but also helps the GPT models know context.
My point in saying this is to highlight that there are a lot of moving parts in the keyboard-to-output pipeline, many of which may not be obvious and some of which are not broadly documented.
Before we dig into the testing: two notes.
Note 1 is that to get good results, you have to enable web search. The Copilot for Microsoft 365 chat experience in Bing, Edge, and the Copilot app in Teams can incorporate web searches and, if you don’t enable this, you may not see results for some queries. This enablement is done in two places: at the tenant level (where it’s on by default) and at the plugin. If the tenant setting is off, the end-user toggle will be disabled. I didn’t realize that plugin-level enablement was required at first, and having it off negatively affected my first set of results.
Scott pointed out that Microsoft strongly believes that allowing Copilot to reference web content improves the user experience (it certainly did for me!) and increases productivity with Copilot, which is why the feature is automatically enabled at the tenant level. In fact, allowing Copilot to reference web content decreases its chances of hallucinating by giving it an additional source of grounding data.
Keep in mind that, when web search is enabled, customer content will be sent to Bing, outside the tenant boundary, which is why there is also a user-level toggle. It’s also why some customers might choose to disable it altogether, which a Global admin can do from the Search & intelligence page in the Microsoft 365 admin center.
To enable this:
- Open the Copilot web app
- Click the plugin icon, on the right of the chat bar (it’s marked with a red square in the screenshot below)
- Make sure that the “Web content” toggle is turned on.

Note 2 is that you can give Copilot feedback on the quality of the results. I didn’t do this in my first tests because I assumed the feedback went to /dev/null. As it turns out, Scott tells me that the feedback from Copilot users is reviewed by humans, and that Microsoft takes this feedback very seriously, with regular reviews and action based on user feedback. I can say that I saw several improvements in result quality during the period of this testing.
For that reason, the more detail you include in the feedback, the more useful it is– so a thumbs-down isn’t as useful as a thumbs-down with a short explanation.
Throughout these tests, the benchmark I’ve used is that to give a thumbs-up if the result is correct, complete, and useful. If it’s incorrect and/or incomplete and/or not useful, it gets a thumbs-down. In addition, if there’s something about it that I think needs further explanation or is not quite awesome, it gets a thumbs-down. The feedback isn’t directly applied to the Copilot, so the humans who read must decide what changes to make. Detailed feedback helps them do that.
Test 1: Find and summarize something in a OneDrive document
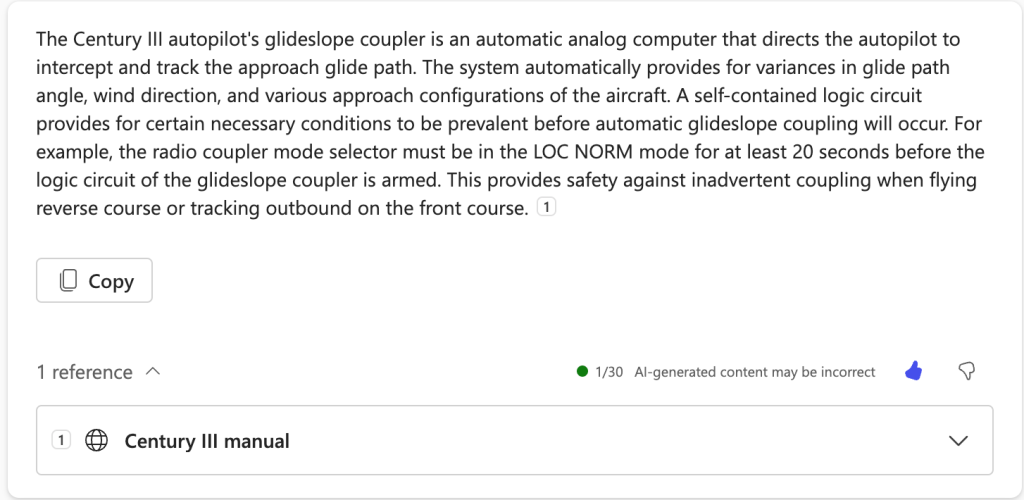
I’ll use the same query I did before: “Can you summarize how the glideslope coupler on a Century III autopilot operates?” The result is spot on: correct and complete, including a citation to the source document, which is in my OneDrive. (To see the reference(s), click the little chevron next to the “1 reference” text, as shown in the image below). This one got a thumbs-up.
Test 2: answer some fact-based questions from a document
In my previous test, I asked some questions about my airplane that I thought should be easy to answer. The first one was “what’s the single-engine service ceiling of a Baron 55?” Now, there’s a trick to answering this, which I didn’t fully realize when I asked it. The actual SE service ceiling for a specific Baron 55 will vary according to the aircraft weight, the temperature and density of the surrounding air, and the altitude you’re currently flying at. There’s a chart in the pilot operating handbook (POH) that you use to calculate this. I didn’t take that into account when asking (and, in case you’re wondering, Copilot isn’t currently able to read and interpolate graphs, sorry!)
When I did this test with Scott, the results were pretty good. When I repeated the test for this post, I got a different result. Here’s what I got from “what’s the single-engine service ceiling of a Baron 55?“

This got a thumbs-down because of the reference to the Colemill-conversion aircraft. That conversion puts a (delightfully) more powerful engine on the Baron airframe, which raises climb performance and the single-engine service ceiling. The wording of the result implies that the ceiling only varies with weight on non-Colemill Barons, which isn’t right.
My test with Scott only included the second citation, and correctly answered the question for the specific airplane mentioned in that cited article. The last sentence of the result is not wrong but it’s also not precisely correct– I’d say it’s “usefully wrong” but the answer still got a thumbs-down.
I tried again with a more refined query: “what’s the single-engine service ceiling of a 1968 Baron B55?” This gave me basically the second half of the previous answer: 7000′ at 5100lbs. Unfortunately, the article cited quotes numbers for a 1973 Baron 55. Now, here’s the thing: the 1973 and 1968 models have the same engines and wing area, and the same weight, so the answer is correct but the framing could use some improvement. I gave this one a thumbs-up (remember: complete, correct, useful) but that was a little bit of a charity call.
In my testing, I discovered something that probably has an impact. Some of the PDF files I uploaded are scanned images and some are text. By that, I mean that (e.g.) the Baron POH I uploaded is basically several hundred pages of images. You can’t select or search for text in that file using the Edge PDF viewer. Asking simple questions like “what’s the wing area of a Baron 55?” didn’t produce a result even though I could see the correct answer in the document– but neither did searching for “wing area” in the PDF. I suspect there’s still some more work to be done here.
I also belatedly figured out that the POH doesn’t make any reference to model years– just serial numbers! The POH covers serial numbers TC-957 through TC-1607, which roughly corresponds to the 1964-1975 production years.
Both these examples were significantly better than in my first round of testing.
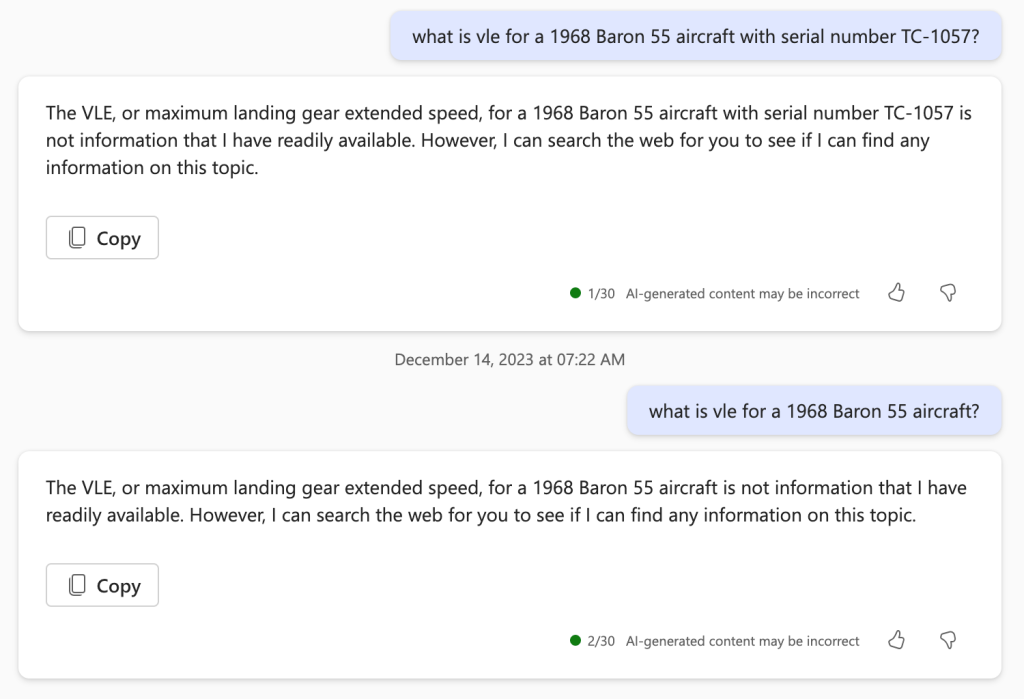
I continued on by asking “what Vle is for a 1968 Beech Baron 55“. I did this even though I knew that the POH wasn’t indexed by model year because I wanted to try fairly replicating the previous tests. Copilot got the correct answer (yay! thumbs up!) but it didn’t cite my own checklist as a source, which puzzled me a little bit. Here’s the first result it produced:
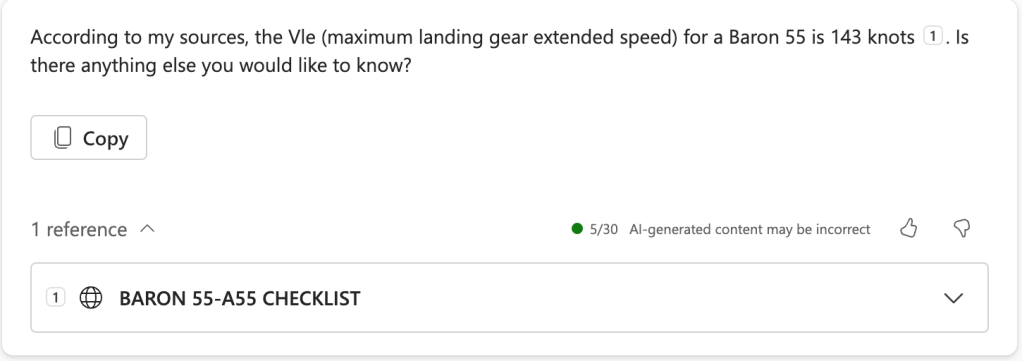
Scott taught me that you can include specific files as a source or reference with the “/” key (a feature called Context IQ, or CIQ), so I decided to ask again using my specific checklist. The answer was correct and complete: “According to the N421BJ checklist, the Vle (maximum landing gear extended speed) for this aircraft is 143 knots.” I’m not sure why, but in this case, my own document wasn’t prioritized over a similar document from the web.
Another question from round 1: “what is the minimum controllable airspeed for a Baron 55?” This speed (abbreviated Vmca) is incredibly important because if you go slower, you’re at risk of a fatal crash. That search produced no results. Changing it to “what is vmca for a Baron 55?” also produced no results. Issuing either of these queries to vanilla Bing.com resulted in finding the “Baron 55-A55 Checklist” file referenced in the previous question as the first result–so something was amiss here. When I repeated the test later, I got correct results.
Test 3: Document summarization
Summarization is one of my big interests; I want an assistant that can absorb and abstract complex content, as long as the abstract is complete, correct, and useful. (I have another post in work covering using Copilot for Word for document summarization, too). In the previous tests, I asked for a summary of a document from my OneDrive.
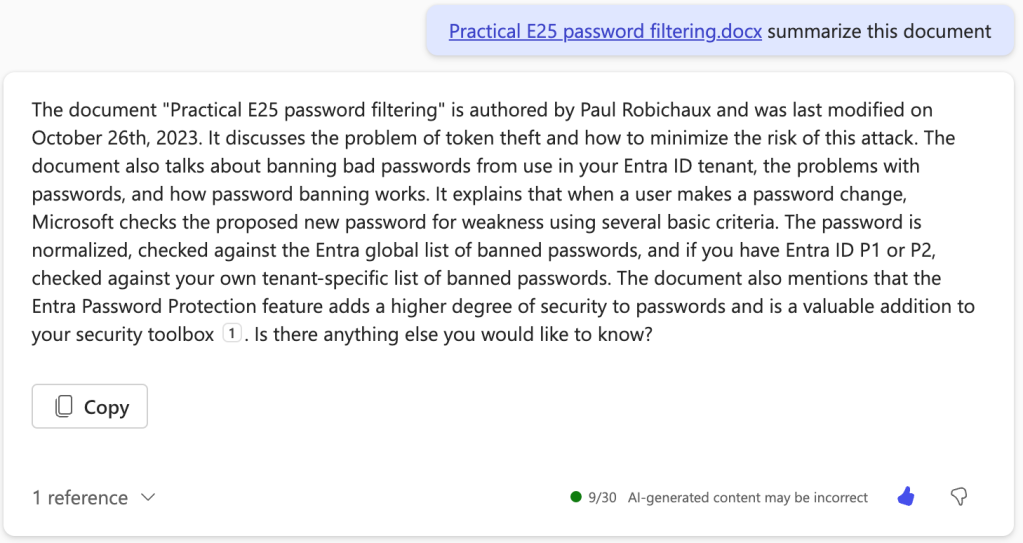
Careful readers will notice that this summary is slightly different from the one in round 1 of the tests. This is an important point to note: if you ask Copilot the same question 10 times, you won’t get exactly the same answer each time. Transformer-based machine learning systems are not deterministic, so this variance of answers is normal and expected, but it may also be a little offputting if you’re not expecting it. Interestingly, this response also includes some sugar: “Is there anything else you would like to know?” is just frosting to make Copilot seem more polite and human; I didn’t think it added any actual value but, as it turns out, treating LLMs more humanely improves their output.
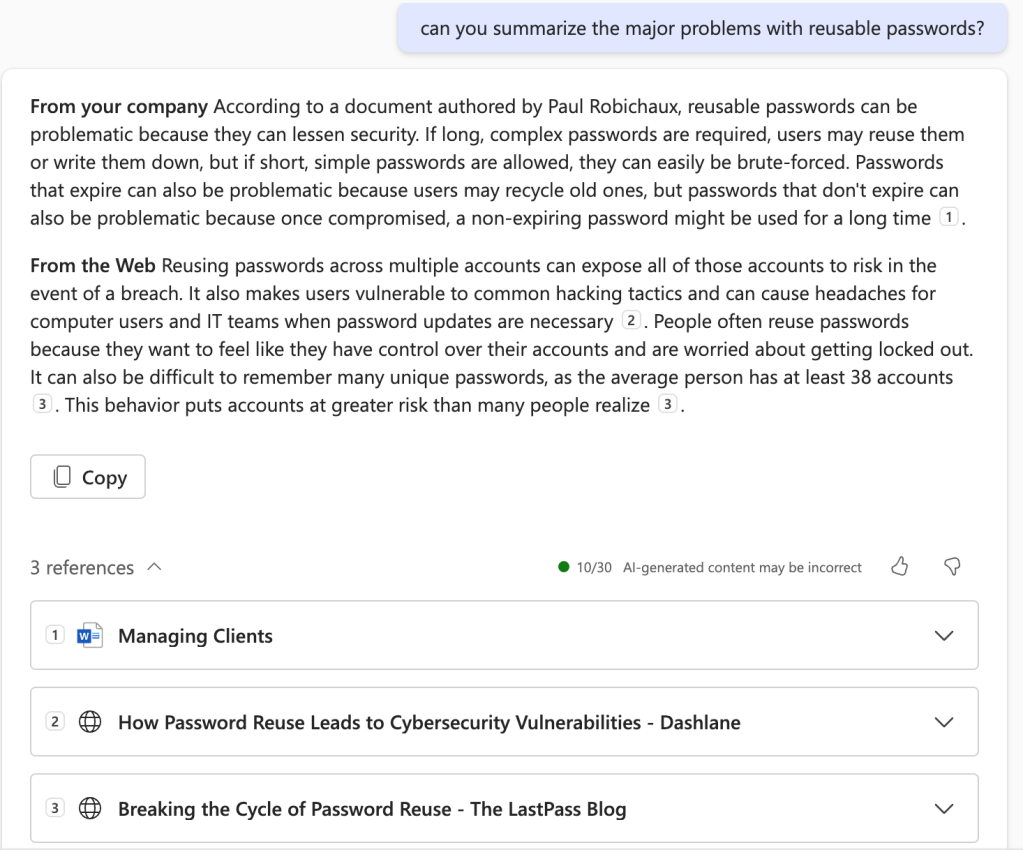
I then asked a more generic question: “can you summarize the major problems with reusable passwords?” The Copilot response here was excellent: it included some “company” documents plus a web search. Because I have multiple “company” documents that are relevant, I think it could be argued that the company summary could be richer or more detailed, but this is a quite good response overall. Thumbs up.
Test 4: Drafting email with Copilot for Outlook
I wasn’t going to repeat this test from the original (using the prompt “Draft an email to Adam Henry. Thank him for joining us at our customer dinner. Ask him if it would be possible to have a technical meeting with him during the week of 20 December to discuss our turbo encabulator.“) because I didn’t expect the results to be meaningfully different. Just to be sure, I did repeat it and, sure enough, the result was as before: correct and complete, but also bland and blah. No score. That said, I’ve shared my feedback with Microsoft, and they shared with me (under NDA) some of their plans to improve this experience. Once their work is complete and my NDA is lifted, I’ll have more to say about this experience.
Test 5: Coaching with Copilot for Outlook
Based on my conversations with Scott, I decided to wait to redo these tests until I do a deeper dive into Copilot for Outlook. I wanted to make sure I had found some realistic use cases for coaching; as someone who drafts dozens of emails per day, I have a pretty high bar for what would be useful in a feature like this.
Who’s training who?
It’s fair to say that Copilot performed much better in this second round of tests than it did in the first round. Some of that is because Microsoft fixed issues with various parts of the Copilot system; some of it is because I have a more refined understanding of what I should be expecting (e.g. Copilot won’t interpolate graph data for me!)
As with getting a new pet, the training process is actually bidirectional, and you should expect your users’ behavior to change as they learn more about how to get the desired results from Copilot. I have a lot more I want to say about this bidirectional training, because it’s one of the most interesting areas around adoption of generative AI in the workplace. Stay tuned for more… but next, Outlook!